Datengestützte Entscheidungen treffen
Datengestützte Entscheidungen treffen

Fakten- und Dimensionstabellen in Power BI: Wie Sie mit
Sternen ⭐ und
Schneeflocken ❄️
die Performance innerhalb
Ihrer Datenanalyse optimieren
Sternen ⭐
Schneeflocken ❄️
die
Ihrer
In der Datenanalyse benötigen Sie Daten aus den unterschiedlichsten Datenquellen. Da kann es schnell passieren, dass Ihre Datenmodelle sehr komplex werden, wodurch wiederum die Performance leiden kann. Insbesondere in einem Unternehmen, bei dem die Kundschaft im Mittelpunkt steht, ist es wichtig, dass es möglichst wenig Verzögerungen gibt. Mithilfe zweier mehrdimensionaler Schemata lässt sich die Modellierung Ihrer Daten sehr einfach optimieren.
Datenmodelle in Power BI aufbauen
Um ein Datenmodell in Power BI sauber aufzubauen benötigen Sie einen zentralen Sammelpunkt für Ihre Daten – das Data Warehouse. Dabei handelt es sich praktisch um ein berichtsorientiertes, multidimensionales Datenlager. Bei der Erstellung Ihres Data Warehouses können Sie sich an verschiedenen Datenmodellen orientieren.
Betrachten Sie zunächst einmal folgende beispielhafte Fragestellung:
Wie viel Umsatz hat die ‘Knusperkeks GmbH’ im November 2022 mit der Produktkategorie ‘Weihnachten’ generiert?
Anhand der Frage erkennen Sie bereits, dass sich der Umsatz aus verschiedenen Blickwinkeln betrachten lässt. Einmal betrachten Sie ihn im Hinblick auf den Zeitraum, einmal mit Blick auf die Kundschaft (im folgenden Text sowie in den Abbildungen vereinfacht als „Kunde“ bezeichnet), welche den Umsatz erzielt hat, und einmal schauen Sie auf die entsprechende Produktkategorie.
Bei der Kennzahl ‘Umsatz’ handelt es sich um einen Fakt, wohingegen ‘Zeitraum’ (Monat), ‘Kunde’ und ‘Produktkategorie’ Dimensionen sind.

Folge 85
Wenn Sie auf das Stern- oder das Schneeflocken-Schema zurückgreifen, können Sie sehr komplexe …
Wenn Sie auf das Stern- oder das Schneeflocken-Schema zurückgreifen, können Sie sehr komplexe Datenmodelle in Power BI ganz einfach optimieren – und somit die Performance und Effizienz Ihrer Datenanalyse erhöhen. Wie unterscheiden sich die Modelle und welches ist das richtige für Sie?
Mehr anzeigen… Weniger anzeigen…Fakten – was ist das?
Fakten – auch Measures, Metriken oder Messwerte – sind kennzahlenbasierte Werte, die im Mittelpunkt Ihrer Datenanalyse stehen. Diese haben die Aufgabe, relevante Zusammenhänge in verdichteter, quantitativ messbarer Form abzubilden. Es handelt sich hierbei immer um numerische Werte, also Zahlen.
Alle relevanten Fakten werden in einer Faktentabelle zusammengefasst. Im Beispiel heißt die Faktentabelle „faktWertposten“. Weiterführende Fakten könnten etwa Kosten oder Verkaufszahlen sein.
Neben den Fakten werden in der Faktentabelle Fremdschlüssel integriert, wodurch Sie Zugriff auf weitere Tabellen mit weiterführenden Informationen erhalten. Hierbei spricht man von Dimensionstabellen.
Dimensionen – was ist das?
Dimensionen sind deskriptive Daten. Sie beschreiben die Daten in der Faktentabelle und ermöglichen unterschiedliche Sichten auf die Fakten. Dazu können Sie in Ihrer Auswertung Fakten nach Dimensionen gruppieren und analysieren. Meistens resultieren Dimensionen aus Stammdaten.
Dimensionstabellen speichern somit die Dimensionen, die die Daten in Ihrer Faktentabelle genauer beschreiben. Mithilfe des ebenfalls in der Dimensionstabelle hinterlegten Primärschlüssels wird eine Beziehung zwischen der Dimensionstabelle und der Faktentabelle ermöglicht. Infolgedessen haben Sie die Möglichkeit bei Ihrer Datenanalyse Spalten aus der Faktentabelle auszuwählen und diese mit den Informationen aus der Dimensionstabelle zu erweitern.
So können Sie im Beispiel anhand der hinterlegten ‘Kunden-ID’ weitere Informationen wie den Namen oder die Region des jeweiligen Debitors in Ihre Analyse integrieren.
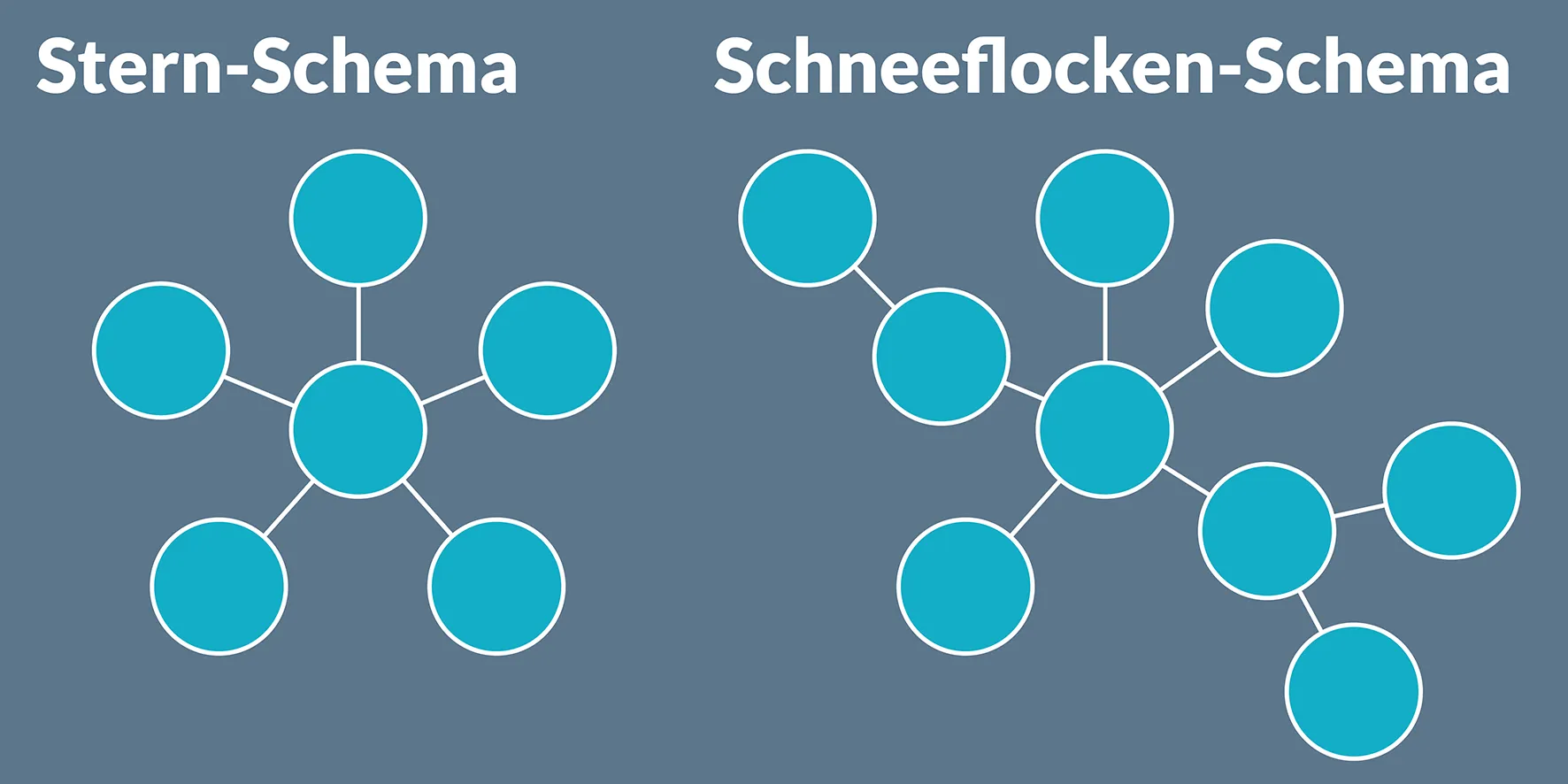
Das Stern-Schema: Eine Faktentabelle mit Dimensionstabellen verknüpfen
Fakten- und Dimensionstabellen sind Bestandteile des Stern-Schemas (Star-Schema), welches eines der Datenmodelle ist, die sich besonders für Power BI anbieten. Das Schema setzt sich immer aus einer Faktentabelle und mehreren Dimensionstabellen zusammen. Die Faktentabelle steht dabei im Mittelpunkt und um sie herum ordnen sich die Dimensionstabellen an. Diese Anordnung erinnert optisch an die Form eines Sterns – so kam es auch zu dem Namen des Modells.
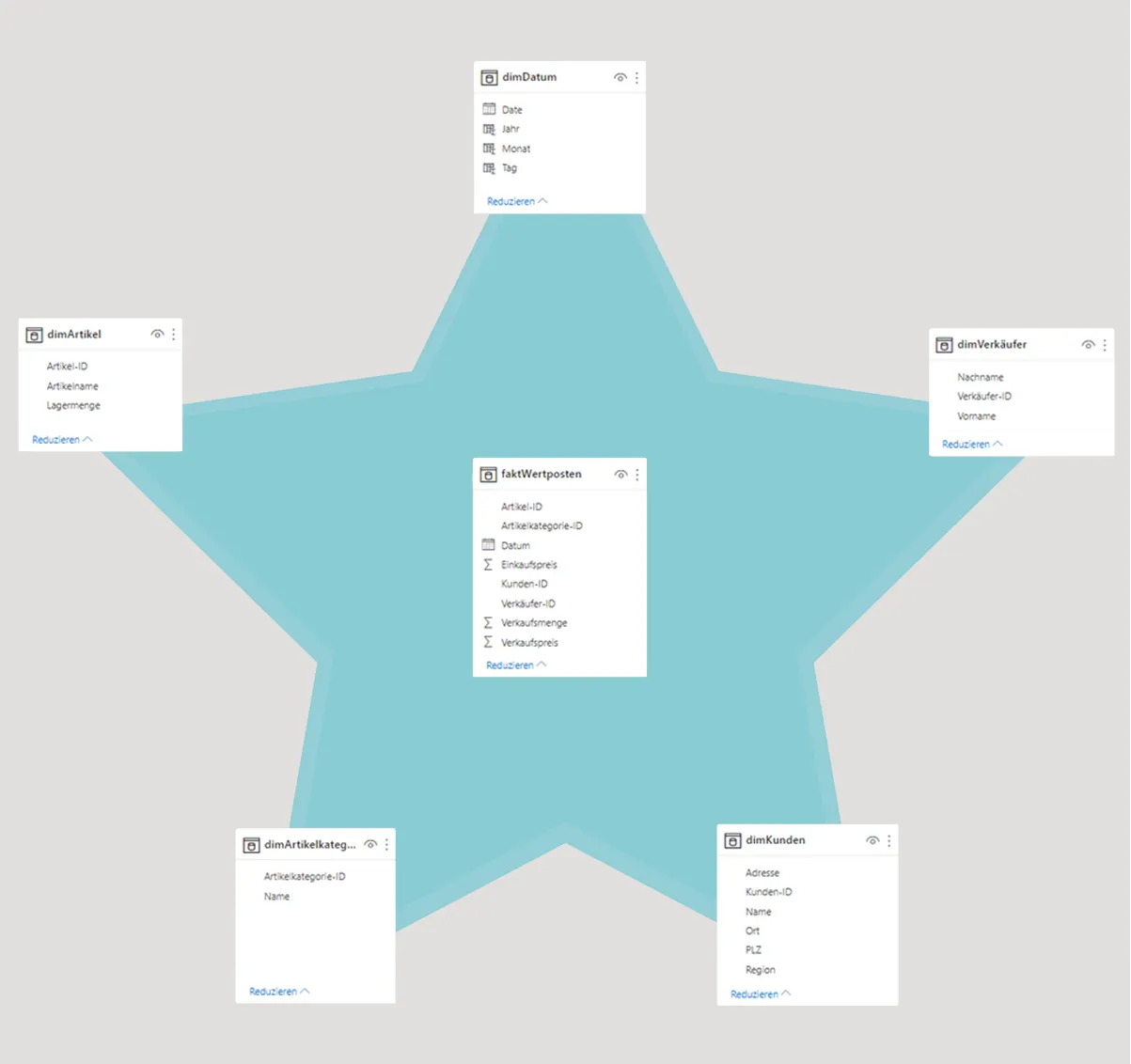
Die Faktentabelle „faktWertposten“ im Beispiel enthält neben dem Datum die Fremdschlüssel ‘Artikel-ID’, ‘Artikelkategorie-ID’, ‘Kunden-ID’ und ‘Verkäufer-ID’. Mithilfe dieser Schlüssel wird eine Beziehung zu den jeweiligen Dimensionstabellen hergestellt, aus denen die Informationen stammen.
Das Stern-Schema – Ihre Benefits
-
Hohe Performance
Sie können Abfragen sehr schnell verarbeiten. -
Hohe Anwendungsfreundlichkeit dank Einfachheit des Modells
Die Konzeptionierung ist einfach umzusetzen und das Modell ist verständlich und nachvollziehbar. -
Kurze Ladezeiten aufgrund des geringeren Datenvolumens
Die Dimensionstabellen sind im Verhältnis zu den Faktentabellen sehr klein. Dadurch verkürzen sich die Ladezeiten. -
Einfache JOIN-Möglichkeiten
In Power BI können Sie auf verschiedene Weisen Tabellen zusammenführen (JOIN), wenn diese über Spalten mit identischen Inhalten verfügen. Mithilfe eines Stern-Schemas sind diese Abfragen leicht zu integrieren.
Mögliche Schwächen des Modells
-
Ggf. verringerte Performance durch irrelevante Daten
Möglicherweise enthalten die Dimensionstabellen Informationen, die für Ihre Berichte irrelevant sind. Dadurch kann sich die Performance verschlechtern. -
Wiederholungen aufgrund denormalisierter Daten
In den Dimensionstabellen können sich Informationen aus mehreren Feldern in den Zeilen wiederholen (denormalisierte Daten). Das Gegenstück dazu sind die normalisierten Daten (mehr dazu im nächsten Abschnitt).
Das Schneeflocken-Schema: Die Dimensionstabellen weiter spezifizieren
Das Schneeflocken-Schema (Snowflake-Schema) ist eine Weiterentwicklung des Stern-Schemas. Der Übergang vom einen zum anderen Modell ist dabei fließend und es finden sich einige Gemeinsamkeiten. Im Zentrum steht auch hier die Faktentabelle, wobei die Dimensionstabellen mit dieser in einer Beziehung stehen. Jedoch haben Sie im Snowflake-Schema die Möglichkeit, noch weitere Hierarchiestufen (Folgedimensionen) für die Dimensionstabellen zu integrieren. Doppelte Daten aus den bereits bekannten großen Dimensionstabellen des Stern-Schema-Beispiels können Sie in neue kleinere Tabellen unterteilen. Dieser Vorgang heißt „Normalisierung“. Aufgrund der zusätzlichen Verzweigungen entsteht die Schneeflocken-Optik.
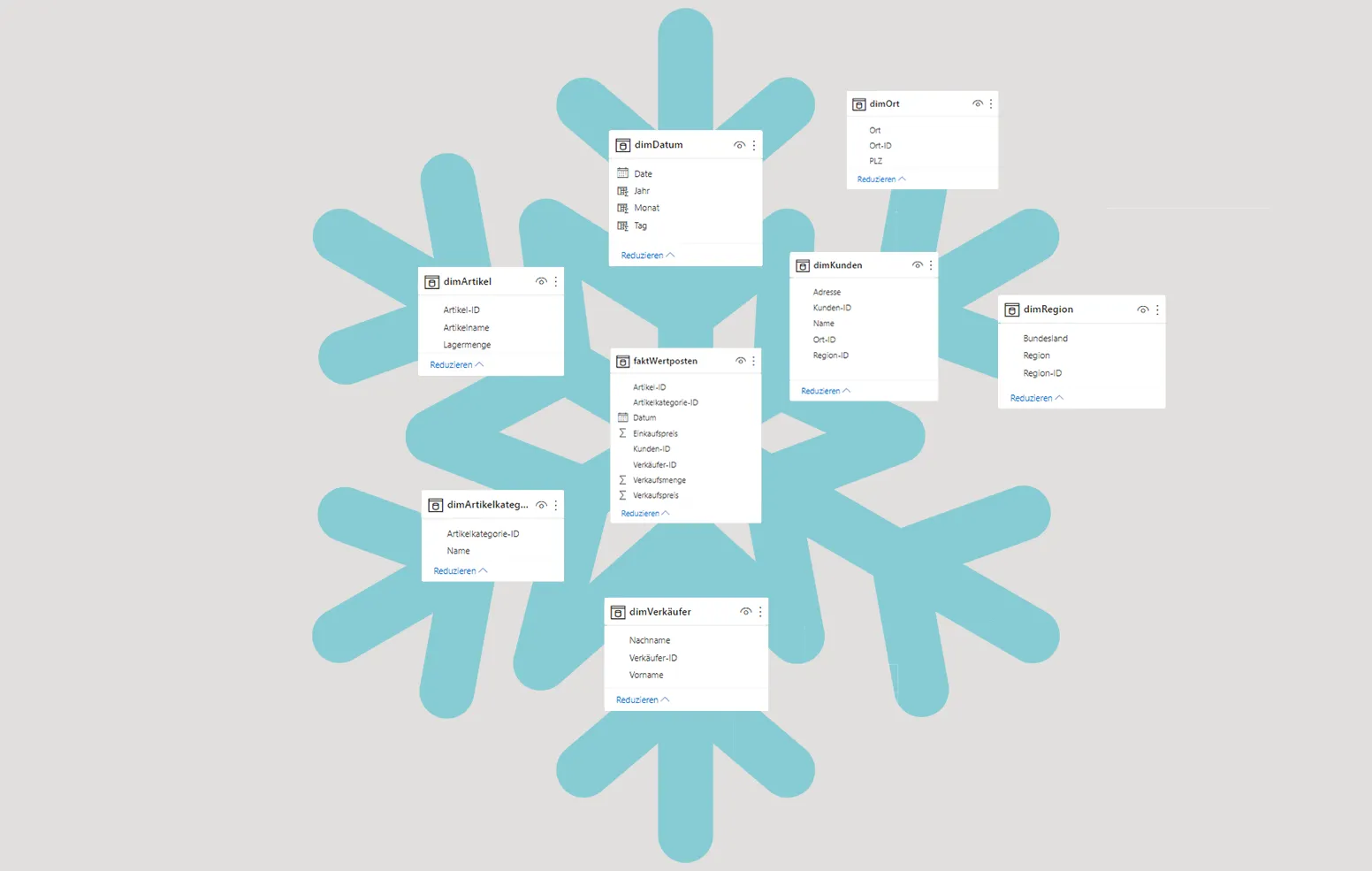
Auch hier enthält die Faktentabelle „Wertposten“ aus dem Beispiel neben dem Datum die Fremdschlüssel ‘Artikel-ID’, ‘Artikelkategorie-ID’, ‘Kunden-ID’ und ‘Verkäufer-ID’. Zusätzlich beinhaltet die Dimensionstabelle „dimKunden“ noch die Fremdschlüssel ‘Ort-ID’ und ‘Region-ID’. Damit können nun ebenfalls weitere Informationen aus den Folgedimensionstabellen in die Analyse einfließen.
Schneeflocken-Schema – Ihre Benefits (im Vergleich zum Stern-Schema)
-
Geringeres Datenvolumen durch Normalisierung
Das Modell enthält aufgrund der Normalisierung keine redundanten Daten mehr und Sie verbrauchen weniger Datenvolumen. -
Strukturiertere Datenmengen durch weitere Verzweigungen
Durch die zusätzlichen Verzweigungen sind Ihre Daten noch feiner strukturiert.
Mögliche Schwächen des Modells
-
Ggf. Performanceeinbußen
Die zusätzlichen Beziehungen zwischen den Dimensionstabellen führen im Vergleich zum Star-Schema zu einer höheren Komplexität, wodurch die Performance wiederum abnehmen kann. -
Schwierigere Konzeptionierung durch komplexere Struktur
Das liegt zum einen daran, dass die Anzahl an Tabellen im Modell erhöht ist. Zum anderen kann ein Mehraufwand entstehen, wenn Sie Änderungen im Modell durchführen, da dies eine Reorganisation der Tabellen erfordert.
Welches Modell ist das richtige für Sie?
Je nach Datenbasis bietet sich entweder das Stern- oder das Schneeflocken-Schema an. So ist ein Stern-Schema meist die bessere Wahl, wenn Sie ein einfaches Design mit vergleichsweise wenigen Fremdschlüsseln sowie einer schnellen Verarbeitung benötigen. Aufgrund seiner Einfachheit und Flexibilität ist es in der Praxis besonders beliebt. Das etwas komplexere Snowflake-Schema eignet sich hingegen eher, sollten Sie Wert auf normalisierte Daten und eine feinere Struktur legen.
Mit Sternen und Schneeflocken Umwege vermeiden – und somit die Performance und Effizienz Ihrer Datenanalyse erhöhen
Die zentralen Vorteile, wenn Sie ein Stern-Schema bzw. ein Schneeflocken-Schema zur Erstellung Ihrer Datenmodelle verwenden, bestehen darin, dass Sie irrelevante Daten ausfindig machen und aussortieren, Redundanzen vermeiden und somit die Performance innerhalb Ihrer Datenanalyse optimieren. Sie verhindern Verzögerungen in Ihrer Analyse und arbeiten effizienter. Dazu tragen zudem auch die Anwendungsfreundlichkeit sowie die hohe Übersichtlichkeit der Modelle bei.
Das Prinzip der Performance-Optimierung wird noch einmal ganz besonders an diesem Alltagsbeispiel deutlich: Sie planen, am Wochenende nacheinander zwei Schulfreunde und Ihre Großeltern zu besuchen. Sie starten von Münster aus. Ihr Freund Fridolin wohnt in Kiel, Ferdinand in Berlin und Ihre Großeltern leben in München.
Da Sie natürlich so wenig Zeit wie möglich im Auto sitzen möchten und lieber die Momente mit Freunden und Familie verbringen wollen, planen Sie Ihre Route entsprechend: Sie fahren von Münster über Kiel nach Berlin und anschließend nach München. Würden Sie stattdessen von Kiel nach München fahren und dann nach Berlin, wäre dies nicht nur ein erhöhter zeitlicher Aufwand, sondern es würde Sie auch viele weitere Kilometer kosten.
Genauso ist es in Ihrer Datenanalyse. So sollten Sie auch wenn Sie auf Ihre Daten zugreifen, Umwege vermeiden. Hier ist es Ihr Ziel, zu verhindern, dass durch ein suboptimales Datenmodell die Performance Ihres Dashboards leidet. Stattdessen sollte Ihre Analyse mithilfe Ihrer Power BI-Berichte ihr volles Potential entfallen können.